TrailBuddy: Using AI to Create a Predictive Trail Conditions App


TrailBuddy helps plan your next outdoor adventure by using machine learning to combine weather, soil, and location data to predict if a trail is dry or muddy.
Viget is full of outdoor enthusiasts and, of course, technologists. For this year's Pointless Weekend, we brought these passions together to build TrailBuddy. This app aims to solve that eternal question: Is my favorite trail dry so I can go hike/run/ride?
While getting muddy might rekindle fond childhood memories for some, exposing your gear to the elements isn’t great – it’s bad for your equipment and can cause long-term, and potentially expensive, damage to the trail.
There are some trail apps out there but we wanted one that would focus on current conditions. Currently, our favorites trail apps, like mtbproject.com, trailrunproject.com, and hikingproject.com -- all owned by REI, rely on user-reported conditions. While this can be effective, the reports are frequently unreliable, as condition reports can become outdated in just a few days.
Our goal was to solve this problem by building an app that brought together location, soil type, and weather history data to create on-demand condition predictions for any trail in the US.
We built an initial version of TrailBuddy by tapping into several readily-available APIs, then running the combined data through a machine learning algorithm. (Oh, and also by bringing together a bunch of smart and motivated people and combining them with pizza and some of the magic that is our Pointless Weekends. We'll share the other Pointless Project, Scurry, with you soon.)
The quest for data.
We knew from the start this app would require data from a number of sources. As previously mentioned, we used REI’s APIs (i.e. https://www.hikingproject.com/data) as the source for basic trail information. We used the trails’ latitude and longitude coordinates as well as its elevation to query weather and soil type. We also found data points such as a trail’s total distance to be relevant to our app users and decided to include that on the front-end, too. Since we wanted to go beyond relying solely on user-reported metrics, which is how REI’s current MTB project works, we came up with a list of factors that could affect the trail for that day.
First on that list was weather.
We not only considered the impacts of the current forecast, but we also looked at the previous day’s forecast. For example, it’s safe to assume that if it’s currently raining or had been raining over the last several days, it would likely lead to muddy and unfavorable conditions for that trail. We utilized the DarkSky API (https://darksky.net/dev) to get the weather forecasts for that day, as well as the records for previous days. This included expected information, like temperature and precipitation chance. It also included some interesting data points that we realized may be factors, like precipitation intensity, cloud cover, and UV index.
But weather alone can’t predict how muddy or dry a trail will be. To determine that for sure, we also wanted to use soil data to help predict how well a trail’s unique soil composition recovers after precipitation. Similar amounts of rain on trails of very different soil types could lead to vastly different trail conditions. A more clay-based soil would hold water much longer, and therefore be much more unfavorable, than loamy soil. Finding a reliable source for soil type and soil drainage proved incredibly difficult. After many hours, we finally found a source through the USDA that we could use. As a side note—the USDA keeps track of lots of data points on soil information that’s actually pretty interesting! We can’t say we’re soil experts but, we felt like we got pretty close.

Putting our design hats on.
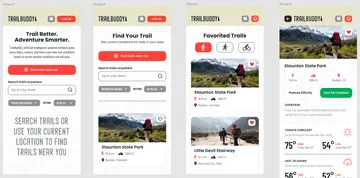
From the very first pitch for this app, TrailBuddy’s main differentiator to peer trail resources is its ability to surface real-time information, reliably, and simply. For as complicated as the technology needed to collect and interpret information, the front-end app design needed to be clean and unencumbered.
We thought about how users would naturally look for information when setting out to find a trail and what factors they’d think about when doing so. We posed questions like:
- How easy or difficult of a trail are they looking for?
- How long is this trail?
- What does the trail look like?
- How far away is the trail in relation to my location?
- For what activity am I needing a trail for?
- Is this a trail I’d want to come back to in the future?
By putting ourselves in our users’ shoes we quickly identified key features TrailBuddy needed to have to be relevant and useful. First, we needed filtering, so users could filter between difficulty and distance to narrow down their results to fit the activity level. Next, we needed a way to look up trails by activity type—mountain biking, hiking, and running are all types of activities REI’s MTB API tracks already so those made sense as a starting point. And lastly, we needed a way for the app to find trails based on your location; or at the very least the ability to find a trail within a certain distance of your current location.
Using machine learning to predict trail conditions.
As stated earlier, none of us are actual soil or data scientists. So, in order to achieve the real-time conditions reporting TrailBuddy promised, we’d decided to leverage machine learning to make predictions for us. Digging into the utility of machine learning was a first for all of us on this team. Luckily, there was an excellent tutorial that laid out the basics of building an ML model in Python. Provided a CSV file with inputs in the left columns, and the desired output on the right, the script we generated was able to test out multiple different model strategies, and output the effectiveness of each in predicting results, shown below.
We assembled all of the historical weather and soil data we could find for a given latitude/longitude coordinate, compiled a 1000 * 100 sized CSV, ran it through the Python evaluator, and found that the CART and SVM models consistently outranked the others in terms of predicting trail status. In other words, we found a working model for which to run our data through and get (hopefully) reliable predictions from. The next step was to figure out which data fields were actually critical in predicting the trail status. The more we could refine our data set, the faster and smarter our predictive model could become.
We pulled in some Ruby code to take the original (and quite massive) CSV, and output smaller versions to test with. Now again, we’re no data scientists here but, we were able to cull out a good majority of the data and still get a model that performed at 95% accuracy.
With our trained model in hand, we could serialize that to into a model.pkl file (pkl stands for “pickle”, as in we’ve “pickled” the model), move that file into our Rails app along with it a python script to deserialize it, pass in a dynamic set of data, and generate real-time predictions. At the end of the day, our model has a propensity to predict fantastic trail conditions (about 99% of the time in fact…). Just one of those optimistic machine learning models we guess.
Where we go from here.
It was clear that after two days, our team still wanted to do more. As a first refinement, we’d love to work more with our data set and ML model. Something that was quite surprising during the weekend was that we found we could remove all but two days worth of weather data, and all of the soil data we worked so hard to dig up, and still hit 95% accuracy. Which … doesn’t make a ton of sense. Perhaps the data we chose to predict trail conditions just isn’t a great empirical predictor of trail status. While these are questions too big to solve in just a single weekend, we'd love to spend more time digging into this in a future iteration.