What Blackhat and the NSA Can Teach Us About Content Audits
Todd Moy, Former Senior User Experience Designer
Article Category:
Posted on
Content auditors are like hackers and spooks. Working largely from the outside, we assemble bits of information into a picture of the organization, what it produces, how it operates, what it values, and where it's flawed.
And, like these folks, we also often need to start with incomplete information. Access to the CMS or subject matter experts might be delayed and, rather than twiddling our thumbs in the meantime, we must be resourceful. In addition to manually clicking through a site, I've found that one of the most indispensible tools is also the most pedestrian: Google.
Long a favorite method of spooks and hackers, clever use of Google's Advanced Search Operators can return meaningful information that might be hard to discover otherwise. In particular, I've found two resources helpful in understanding the latent power of Google:
- Johnny Long's Blackhat '05 presentation, Google Hacking for Penetration Testers (PDF).
- The NSA's Untangling the Web: A Guide to Internet Research (PDF) , recently released under a FOIA request
Based on these, I've developed a few go-to queries that I use in conjunction with more typical content auditing tools. While the list below is not comprehensive, I hope it will serve as a catalyst for others (you!) to build upon.
Get a sense of scale
Often, it's important to estimate the number of pages in different sections of the site. This data is best obtained through a CMS export, but, in a pinch, you can restrict a search by subsection and look at the number of results:
site:example.com/section-a
Find subdomains
On a recent project, I found an out-of-date microsite languishing on a subdomain. I wanted to see if any others existed, which I accomplished by using the exclusion operator to return only results that were not within the www domain.
site:example.com -site:www.example.com
Find desktop publishing files
Especially on sites without strong governance, MS Office or PDF files are often used as workarounds for unmet requirements or insufficient training. Exposing such instances leads to productive discussions about requirements and content strategy. You can isolate these files by stringing together the filetype operator with a series of ORs.
filetype:pdf OR filetype:doc OR filetype:xls OR filetype:PPT site:example.com
Pay special attention to the URLs for the results returned. These can point to areas of the site where this strategy is more prevalent.
Find indices
Automated index pages provide a quick way to discover content within a section. Depending on the web server used, these can take on a few different forms. I try both of these:
intitle:index.of site:example.com intext:"[to parent directory]" site:example.com
In addition, I look for sitemaps, both automated and dynamic. These are helpful as checksums to ensure pages aren't skipped.
sitemap site:example.com
Find login forms
Occasionally sites have informal "integration points" -- login forms that simply send users to other applications. Searching the body of pages for terms commonly used in forms can often reveal these access points.
intext:login site:example.com
Searching "login" is a good place to start and it's worth exploring other phrases like "sign in", "username", and "password reset".
Find templated pages
Some template-driven sites expose the template name in the url—usually identifiable through something like:
templatename.aspx?id=231
You can use the inurl operator to isolate these, which is helpful for estimating the volume of a particular content type.
inurl:pressrelease.aspx site:example.com
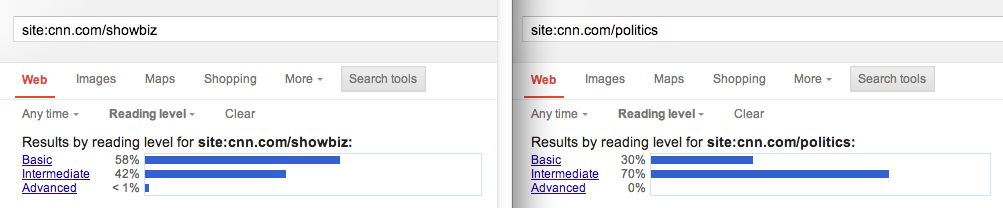
Assess reading level
It can be useful to determine whether content is written at a level appropriate to the audience. To accomplish this, you first conduct a normal query, then use the Search Tools > Reading Level dropdown menu.
I often scope this search to key sections of the site. Doing so may uncover disparities in audiences, content strategies, or authorship across the site.
Find FAQs
While FAQs aren't inherently bad, they can be symptomatic of poor content. In other cases, FAQs can identify tasks that might not have been revealed through user research. So, I look for these specifically.
"frequently asked questions" OR FAQ site:example.com
Find parents for orphans
Usually in the process of an audit, I'll discover orphaned pages that don't clearly map into the information architecture. To determine their usefulness, I use the link: operator to find out what references them.
link:example.com/page-name/ site:example.com
Others?
Hopefully these provided a bit of inspiration for your own content audits. If you have your own tricks, I'd love to hear them. Drop 'em in the comments.