Radical RAG: An Embeddings Experiment
Joshua Pease, Platform Development Technical Director,
Max Myers, Senior Platform Developer,
Nathan Schmidt, Senior UI Developer,
Solomon Hawk, Development Director, and
Lauren Sheridan, Former Product Manager
Article Categories:
Posted on
During Viget's annual hackathon, we dove head first into embeddings, vector similarity, and RAG.
Have you ever searched for something online but struggled to craft the perfect set of keywords to find what you were looking for? At Viget, we create search experiences for our clients all the time. But we often hit one pesky problem: users' search terms often don't align with our clients' content.
Embeddings, semantic search and RAG are exciting new tools that have potential to help.
As part of Viget’s annual hackathon, called Pointless Palooza, our team built a search tool for evaluating the effectiveness of embeddings and RAG. We decided that the perfect data set would be all 2,500+ articles on Viget.com. This is content that our whole company is familiar with, and the task of searching through a blog like ours is a real-world challenge that impacts clients and users alike.
A quick primer #
What are embeddings? #
Unlike large language models (which predict the next word in a sequence based on billions of examples), embedding models transform text, images and other content into "high-dimensional vectors" that numerically represent meaning. While humans are used to just 3 dimensions in our physical world [X, Y, Z], these vectors can contain thousands of dimensions capturing aspects of meaning.
The OpenAI embeddings model we used for Radical RAG has 1536 dimensions. No matter how long or short the text you are embedding, you always get a list of 1536 numbers.
These dimensions aren't simple features like "color" or "size" but abstract concepts representing complex relationships between words. That's what makes embedding models fascinating yet mysterious - they learn these patterns from massive datasets, but we can't easily interpret what each dimension actually represents in human terms.
Vector similarity & semantic search #
Since embeddings are vectors (lists of numbers), we can use math to measure how close they are to each other in this 1536-dimensional space. This powerful approach enables semantic searching based on hundreds of meaning categories, going beyond the simple keyword matching used in traditional search algorithms.
What is RAG? #
Retrieval Augmented Generation (RAG) combines search (retrieval) with LLMs, by using the contents of your search results to shape the LLM generated response. This effectively encourages LLMs to use your specific data and documents instead of relying on its generic training and running the risk of hallucinations. Our Radical RAG project explores the first piece of that puzzle… Retrieval.
Questions, questions, and more questions #
Our team of six had varying levels of knowledge about embeddings and large language models (LLMs), and none of us had any practical experience working with them.
What we did have were questions… lots of questions.
- Do embeddings and vector similarity improve search results?
- Is it cost effective to generate embeddings for a large dataset?
- What kinds of complexity or performance challenges might we encounter?
The calm before the storm #
We met a few days before Pointless to sketch out ideas and get a shared understanding of the individual parts involved in semantic search. In theory… semantic search is as simple as these three steps:
- Generate embeddings for all of your documents.
- When a user submits a search query on your site, generate embeddings for their query.
- Use a vector database to compute the distance between the search query’s embedding and your document embeddings.
Documents that are “closer” to each other in vector space “should” rank higher than content that is further away.
What we built #
After our initial planning meeting, we came away with a tech stack and a high-level architecture for what we were planning to build.
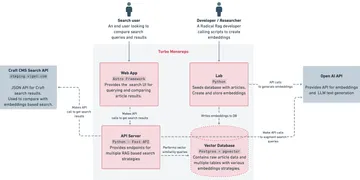
Tech Stack
| Turborepo | A monorepo tool that coordinates running our various applications |
|---|---|
| Python | Powers our search API, and was the language of choice for our scripts & tooling for generating embeddings |
| Fast API | JSON API server |
| SQLModel | Database ORM |
| Alembic | Database migrations |
| Langchain | Data processing & chunking |
| Postgres & pgvector | Stores our article content and serves as our vector database |
| OpenAI | API used to generate embeddings and provide LLM-generated text |
| Astro | JavaScript framework used for the search comparison interface |
| Craft CMS Search API | JSON API for our Viget.com search results, enabling comparison against our new vector-powered search |
A Search UI for Experimenting
With a strong technical foundation in place, we began experimenting with different embedding and chunking techniques. We built out a web app UI to support comparisons of the different methodologies we tried.

- When the user submits a search, we output the Craft CMS search results alongside our vector-powered search for comparison.
- The Search Method dropdown lets the user choose between four different vector-powered search experiments.
- The Similarly Algorithm dropdown lets the user change distance functions used for computing vector similarity. OpenAI recommended Cosine Similarity for their embeddings, but our results were similar between each method.
Want to see some search examples?
View the appendix at the end of this article.
Search Experiments
We experimented with four different search methods.
1. Full Article Search (Alpha)
We named our first set of embeddings “Alpha." With this strategy, we generated one embedding per article.
- When the user submits a search, we generate an embedding for their exact search term.
- That embedding is used to search our vector database for similar articles.
Pros: Simplest code and database schema.
Cons: Embedding models have limited input sizes. Long articles don’t fit within a single chunk. In theory, smaller chunks are more focused on a single topic, which might match better with the user's search query.
2. Keyword Enhanced Search (Alpha)
Using those same alpha embeddings, this strategy uses an LLM to expand upon a user’s search query.
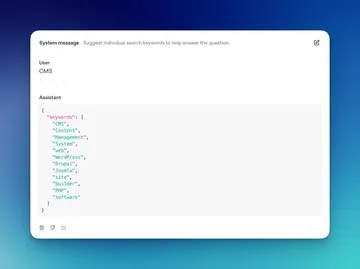
- When the user submits a search, we use
gpt-4o-minito turn the query (such as “CMS”) into a long list of keywords (like "content", "management", "system", "WordPress", "Joomla", "Drupal", etc). - An embedding of the original search plus the LLM-expanded keywords is used to search the vector database.
Pros:
- Results seem a bit more focused compared to “Full Article Search (Alpha)”.
Cons:
- Extra API call to generate the keywords is slower and more expensive than just creating embeddings.
gpt-4o-minidoesn't produce the same keywords for every query, and sometimes they can be completely off base. For the majority of queries, it translates CMS into what we would expect, but occasionally, we would get keywords likeMedicare, Medicaid, coverage, reimbursement, healthcare, compliance, regulations, policy
3. AI-Generated Article Search (Alpha)
This strategy also runs on the Alpha embeddings, but expands the contents of the search query’s embedding to a comparable size as the articles in the Viget blog.
- When the user submits a search, we use
gpt-4o-minito expand the query beyond a simple list of related words and into a full LLM-generated Viget-blog-style article based on the query. - An embedding of the original search plus the fake LLM-generated article is used to search the vector database.
Pros: 🤷♂️ This experiment didn’t seem much better than “Keyword Enhanced Search”
Cons: Using an LLM like gpt-4o-mini to generate a long string of text is even slower and more expensive than the Keyword Enhanced Search method.

4. Chunked Content Search (Beta).
We called our second set of embeddings "Beta." This strategy involved creating embeddings for smaller 1000-token chunks of content, instead of treating each article as a single chunk that gets a single embedding.
Our hope was that this chunking approach would mean each chunk is focused on a single topic, improving matches for short search queries.
In practice, the results weren’t noticeably different from our Alpha embeddings. However, we won’t write off chunking too quickly. There are so many strategies for creating chunks and using them to improve the retrieval and raking of content - this is really only the tip of the iceberg. Another area for improvement with this method would be to boost results if multiple chunks were found for an article.
What we learned
With only 48 hours from start to finish, we barely scratched the surface of the many possible chunking, embedding and search augmentation techniques available. However, we were pleasantly surprised at how well a simple chunking and embedding strategy performed.
Like other developers have noted, it’s relatively easy to get a first draft of vector search built, but working through edge cases and relevancy tuning is the majority of the work.
Want to see some examples of what these search experiments actually returned? Check out the appendix at the end of this article.
The radical
- Embeddings are cheap. We processed over 2,500 articles (~10 million tokens = ~7.5 million words). By the end of our project we spent roughly $0.20 - $0.30 cents on embeddings.
- “Vibes-based search” works better than we’d hoped. It’s surprising how little code it takes to wire up something that can search with semantic meaning.
- The heavy lifting of machine learning has already been done. Vector databases and embedding models do most of the work for you as a developer. The challenge is to create an effective chunking and relevancy strategy.
The meh
- Processing embeddings takes time. It took around 1h 20m to generate embeddings for our articles. A lot of this time is due to HTTP calls and avoiding rate limits. For large sets of data, Open AI has a batch version of their API that supports asynchronous data processing within a 24-hour window. This can also help to manage costs for embeddings that don’t need to be generated on-demand.
- It’s hard to set reliable cutoffs for results. For a normal database search, if the keywords aren’t in your dataset, you get no results. Not so with embeddings. Bashing random letters into the keyboard still returns results - albeit not very helpful ones.
Unanswered Questions
- Is RAG-based search more effective? It’s hard to draw conclusive “proof” one way or the other. That being said, we found that longer, more conversational questions produced meaningful results where a typical database search would turn up empty.
- How might we standardize and automate the evaluation of search results to enable more effective iteration? Our evaluation process was very manual and subjective. To move quickly and experiment with more techniques we would need an automated way of determining the quality of results. We have seen some examples of developers using LLMs to help evaluate these “fuzzy” problems.
- Why did each technique produce its distinct set of results? Unlike traditional search methods where you can explore the keywords within your database, embeddings are more of a black box of semantic meaning.
Team Takeaways
Joshua
Python was a great fit for this project, even though none of us were particularly experienced. One of the challenges of learning new languages and frameworks is that you don’t know what you don’t know. Quite often you don’t even know what to search for in language and package documentation. Asking an LLM questions was a really good way to get a better grasp of how the various Python libraries worked together. Many times, I didn’t know what to start searching for. In a way… it mirrors our Pointless Project. Embeddings and LLMs provide a way to take fuzzy questions and find the specific information you’re looking for.
Lauren
Before Radical RAG I had heard tell of embeddings, but had not had a chance to dive into the concept. As a product manager I knew I would be leaning on my team to do the heavy lifting in the code, and my goal was to learn as much as possible about what building with RAG and LLMs really entails. My role was to spring into research mode and support the team’s exploration of various embedding strategies, chunking methods, and search and retrieval techniques that could shape our app’s ability to find and generate relevant answers. A definite highlight was running the app locally and seeing, in real-time, how different methodologies changed the search results.
Max
It was fun to work in a different language and experiment with AI. I really enjoyed using python to create a script that generated embeddings while giving the user progress output to the terminal. Also, working across different areas of the app and at different times of the day made it exciting to see the progress that was made when you pulled down new changes. Not to mention, I had no idea what embeddings were before starting and how to compare vectors so I learned a ton!
Nathan
I recently heard about RAG and embeddings and was really excited to learn how it actually worked. By the time I was done building out the frontend we were able to connect it to the API endpoint and start searching. It is fascinating to me to use different search terms and phrases and compare embedding search results right next to results from a Craft database. This exploration opened up a whole new way of thinking about using AI and LLMs in websites and web apps that I am working on.
Sol
I've been exploring AI and machine learning for awhile so I was excited at the opportunity to put some of that background into practice and get some hands on experience with RAG. As a Pointless Weekend veteran, this project interested me because of how exploratory and research-oriented it was. I wasn't sure what we'd be able to accomplish going into it, but I'm super proud of the result and everyone's hard work to bring it to life. My favorite part of Pointless is the collaboration — asking questions and solving problems as a group, seeing how other people work, and struggling together.
Appendix: Search Examples #
While this project was geared toward exploration (rather than evaluation) of search strategies, it's interesting to see the results produced through distinct methods and try to assess their relevance. Below are a few comparisons of the same query across a baseline text search and two different search experiments.
- Craft CMS Search (Baseline)
- Full Article Search (Alpha)
- Keyword Enhanced Search (Alpha)
Search Query: "Alternative to WordPress"
In this example, Keyword Enhanced Search expands our query with the following keywords:
Joomla Drupal Wix Squarepace Weebly Ghost Magento Blogger Shopify Medium Weblow Strikingly Hubspot Zyro TYPO3
| Craft CMS Search (Baseline) | Full Article Search (Alpha) | Keyword Enhanced Search (Alpha) |
|---|---|---|
| Going Headless in 2024: A View of the Headless CMS Landscape | CMS Solutions: Custom-Built on a Framework versus Off-the-Shelf | Wix vs. Weebly vs. Squarespace vs. Wordpress.com |
| Liveblogging: BarCamp DC | Going Off-the-Shelf: WordPress vs. Craft vs. Drupal vs. Shopify | Going Off-the-Shelf: WordPress vs. Craft vs. Drupal vs. Shopify |
| Understanding SEO + SMO (Part 2): Specifics | Lafayette on WordPress | CMS Solutions: Custom-Built on a Framework versus Off-the-Shelf |
| How to Create More Accessible Content, Part 2: Media | Ten Ways to Avoid WordPress Crackery | Choosing a CMS and E-commerce Combination |
| Your Guide to Mobile Publishing Formats: AMP, Facebook Instant Articles, and Apple News | Wix vs. Weebly vs. Squarespace vs. Wordpress.com | Planning a Webflow Project |
Search Query: "CSS"
Craft CMS Search boosts the relevancy of articles that have the search keyword CSS in their title.
Full Article Search (Alpha) isn't all that focused, and returns some really old articles (we aren't ranking based on date).
Keyword Enhanced Search (Alpha) "feels" more relevant and expands our query into the following keywords:
CSS Cascading Style Sheets Styling Frontend development web design HTML Responsive design CSS3 Selectors Flexbox Grid Media queries Animations Variables Preprocessors Sass Bootstrap Layout Typography Transtormation
| Craft CMS Search (Baseline) | Full Article Search (Alpha) | Keyword Enhanced Search (Alpha) |
|---|---|---|
| How Does Viget CSS? | Some Lesser Known Features of LESS | Fluid Breakout Layout with CSS Grid |
| CSS Strategy Square-off | Fix It Fast: Rapid IE6 CSS Debugging | A Case for CSS Columns vs. CSS Grid with Tailwind |
| CSS Flexbox: A Reference | Angled Edges with CSS Masks and Transforms | Beginner’s Guide to Web Animation: Part 1, CSS |
| Practical Uses of CSS3 | BEM, Multiple Modifiers, and Experimenting with Attribute Selectors | Building a Nested Responsive Grid with Sass & Compass |
| Easy Textures with CSS Masks | JS 201: Run a function when a stylesheet finishes loading | How We Designed & Built a View Transition Demo |
Search Query "Cascading Style Sheets"
This is a great example of a search query not being present in our article content.
Full Article Search (Alpha) properly handles the semantic meaning of "Cascading Style Sheets". It also includes a lot of content about LESS and SASS.
Keyword Enhanced Search (Alpha) expands the query into the following keywords:
CSS styling web design frontend styles HTML layout appearance responsive webpage background framework grid typography
| Craft CMS Search (Baseline) | Full Article Search (Alpha) | Keyword Enhanced Search (Alpha) |
|---|---|---|
| The Case for Accessibility | Inline Styles, User Style Sheets and Accessibility | Inline Styles, User Style Sheets and Accessibility |
| Building Viget.com In EE (Part 1) | Sass: A Designer’s Perspective | A Case for CSS Columns vs. CSS Grid with Tailwind |
| Questioning the Status Quo | Some Lesser Known Features of LESS | Check Your Breakpoint using this Simple CSS Snippet |
| CSS Strategy Square-off | Managing CSS & JS in an HTTP/2 World | |
| Managing CSS & JS in an HTTP/2 World | Fluid Breakout Layout with CSS Grid |
Search Query: "Strongly Typed Programming Languages"
We don't have many articles that explicitly mention this search term.
Full Article Search (Alpha) returns some articles about C, but ranks TypeScript lower than we would have hoped.
Keyword Enhanced Search (Alpha) expands the query into the following keywords:
strongly typed programming languages type safety type system type checking type inference statically typed languages dynamically typed languages type error compilation runtime type coercion type annotation
| Craft CMS Search (Baseline) | Full Article Search (Alpha) | Keyword Enhanced Search (Alpha) |
|---|---|---|
| Scala: The Adventure Begins! | OTP: The Fun and Frustration of C | TypeScript Best Practices at Viget |
| Functional Programming in Ruby with Contracts | Why I Chose to Learn C | Typing Components in Svelte |
| The Art of Failing Gracefully | TypeScript Best Practices at Viget | Check your Props! |
| 3 Elixir Language Features I Love | Functional Programming in Ruby with Contracts | |
| Functional Programming in Ruby with Contracts | 3 Elixir Language Features I Love |
Search Query: "What brand of shoes should I buy"
We thought this might trip up our vector search examples and only return articles about branding.
Full Article Search (Alpha) returns some branding only content, but surprisingly finds articles about Shoemakers, Nike and T-Shirts.
Keyword Enhanced Search (Alpha) finds some of our work with DICK'S Sporting Goods and Puma. "What Not to Wearable" even borders on fashion advice. It expanded the query into the following keywords:
shoes brand footwear sneakers boots sandals athletic fashion luxury comfort style durability
| Craft CMS Search (Baseline) | Full Article Search (Alpha) | Keyword Enhanced Search (Alpha) |
|---|---|---|
| "Sell the problem you solve, not the product you offer.” | Why Must The Shoemaker’s Children Go Without Shoes? | Nike’s Branded Storytelling |
| Nike’s Branded Storytelling | DICK’S Sporting Goods Women’s Fitness 2014 Campaign: A Shareable and Shoppable Experience for Women | |
| Crafting the Digital Brand: Social Media’s Role in Brand-Building | Dick’s Sporting Goods Running 2014 Campaign: Launching an Immersive Video LookbookDesigning PUMA | |
| 10 T-Shirts You Want To Buy a Designer | What Not to Wearable: Part 1 | |
| Using Word Association to Select Brand Colors | Relaunching PUMA.com, Startup-Style |
Search Query: "Pepperoni Pizza"
Little did we know that we had an article with both "Pizza" and "Pepperoni" in the content.
Both of our vector based search examples ranked that article as most relevant.
Full Article Search (Alpha) veers off track a bit, showing how challenging it is to filter out irrelevant results from embeddings-based queries.
Keyword Enhanced Search (Alpha) returns more relevant food related content. It expanded the query into the following keywords:
pepperoni pizza ingredients recipe history nutrition origin calories toppings style types dough sauce cheese baking brands restaurants delivery frozen spicy slice Italian American New York Chicago woodfired Neapolitan
| Craft CMS Search (Baseline) | Full Article Search (Alpha) | Keyword Enhanced Search (Alpha) |
|---|---|---|
| Ordering Lunch for a Large Group | Ordering Lunch for a Large Group | Ordering Lunch for a Large Group |
| Provisioning & Deploying a LAMP Wordpress Stack with Sprinkle and Capistrano | Recession Special: 5 Great Sites to Save You Money | |
| Google Pay-Per-Action Ads | Market Like You Mean It | |
| An effective way to use Campfire for team chat (Mac OS X) | Cheese and Burger Branded Utility Microsite | |
| Viget Labs’ Super Pat Featured on Webmonkey | Refreshing a Delectible Brand: Bon Appétit has a New Logo |