Power Tools for Content Inventories
Todd Moy, Former Senior User Experience Designer
Article Category:
Posted on
Spreadsheets, strong coffee, and good ol’ fashioned clicking, cutting, and pasting are tried-and-true tools for conducting content inventories. And despite how pedestrian they are, they do the trick for most sites. Sometimes, however, I need tools that are more efficient, present information differently, or allow more interactive exploration.
To fill these gaps, I've added a few other tools to my repertoire. Because they serve niche purposes, I don't employ them on every project. But having them around helps me stay efficient; hopefully they'll help you too.
Here are four (free!) tools I've been loving recently.
Scraper
The other day, I wanted to pull titles and URLs for hundreds of fellowships, internships, and residencies into a spreadsheet for categorization and annotation. Getting a database dump from the developer was taking too long and I’m too lazy to copy and paste all of that. Plus they were in an orderly format on the site. Gotta be an easier way, right?
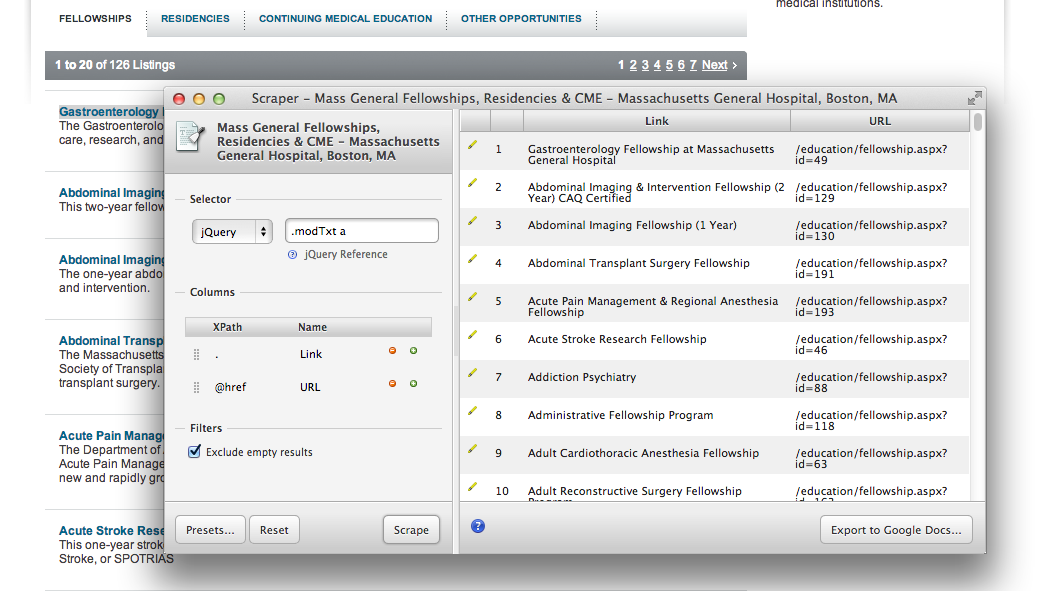
Scraper is a Chrome Extension lets you intelligently extract content from a page. Though it will work on nearly any textual content, it’s particularly well suited for scraping structured lists – say, an index of articles or a collection of products. If the content is marked up predictably, you can probably pull it out with Scraper.
To use it, you right-click an example item on the page and choose "Scrape Similar". It then tries to find that example's siblings on the page. For simple pages this works pretty well out-of-the-box. For more complex content, I use the Jquery-style selector syntax to target exactly the items I want.
Once you’re done, you can export your results directly to Google Sheets.
Grab Them All
A recent project involved site whose content is organized into 70 independent business units. Most units used similar layouts but their content and IA varied widely. There was no good representative sample, so I needed a way to view all the home pages for the business units at once. Viewing them as small mutiples, I surmised, would give me a visceral sense of commonalities and differences.
But screenshot all of them? Ain’t nobody got time for that.
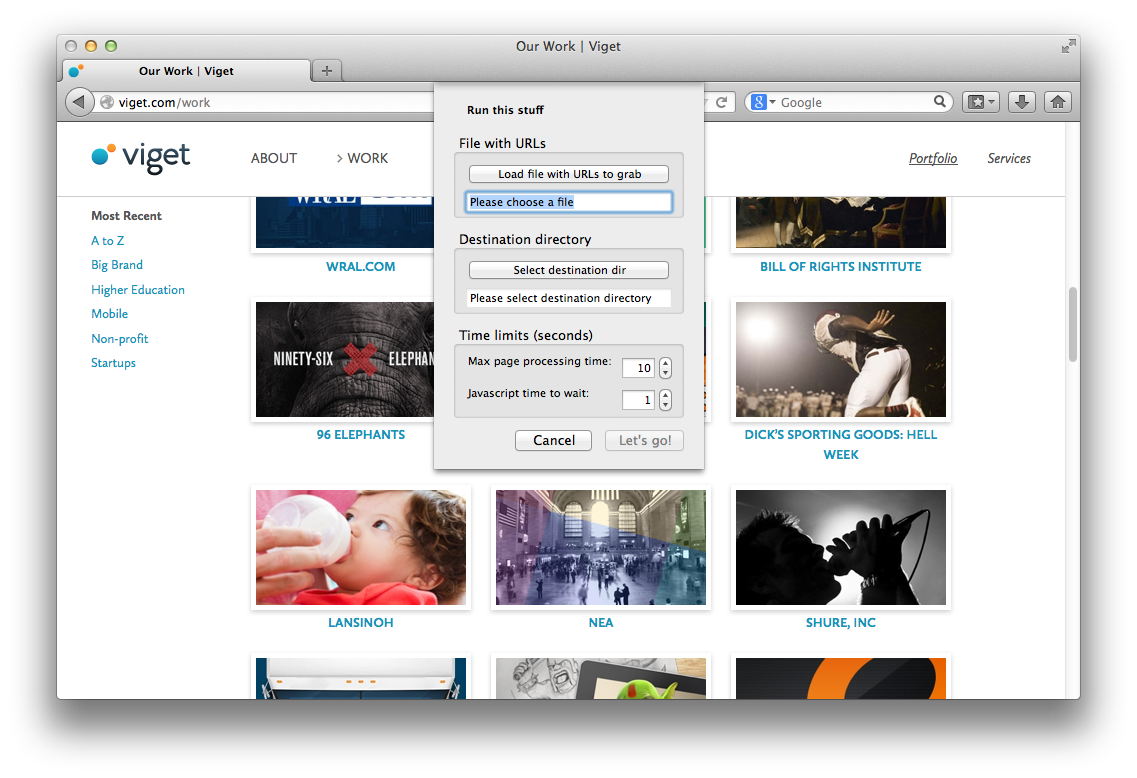
Grab Them All is a Firefox extension that automates the screenshot process. You provide it with a text file of URLs and a destination directory. Once you click “Let’s Go!”, the app sets off and takes screenshots of the entire content of each page. Neat.
I fired up Scraper, grabbed a list of URLs from the business unit listing page, and set Grab Them All loose. A few minutes – and one Sweet ’n’ Salty later, natch – I had a directory full of images.
Google Refine
One big site I worked on totaled over 100k unique pages, many of which were based on unstructured content. Content had been developed over time by a set of authors with little governance. As a result, old content and differences in organization were rampant.
To decompose the problem, I got a .csv dump of every page URL on the site, along with metadata like date edited, last author, and template used. Awesome. When I threw the data at Google Sheets and Numbers, both balked and whined once I started cleaning up and filtering the data. Not Awesome.
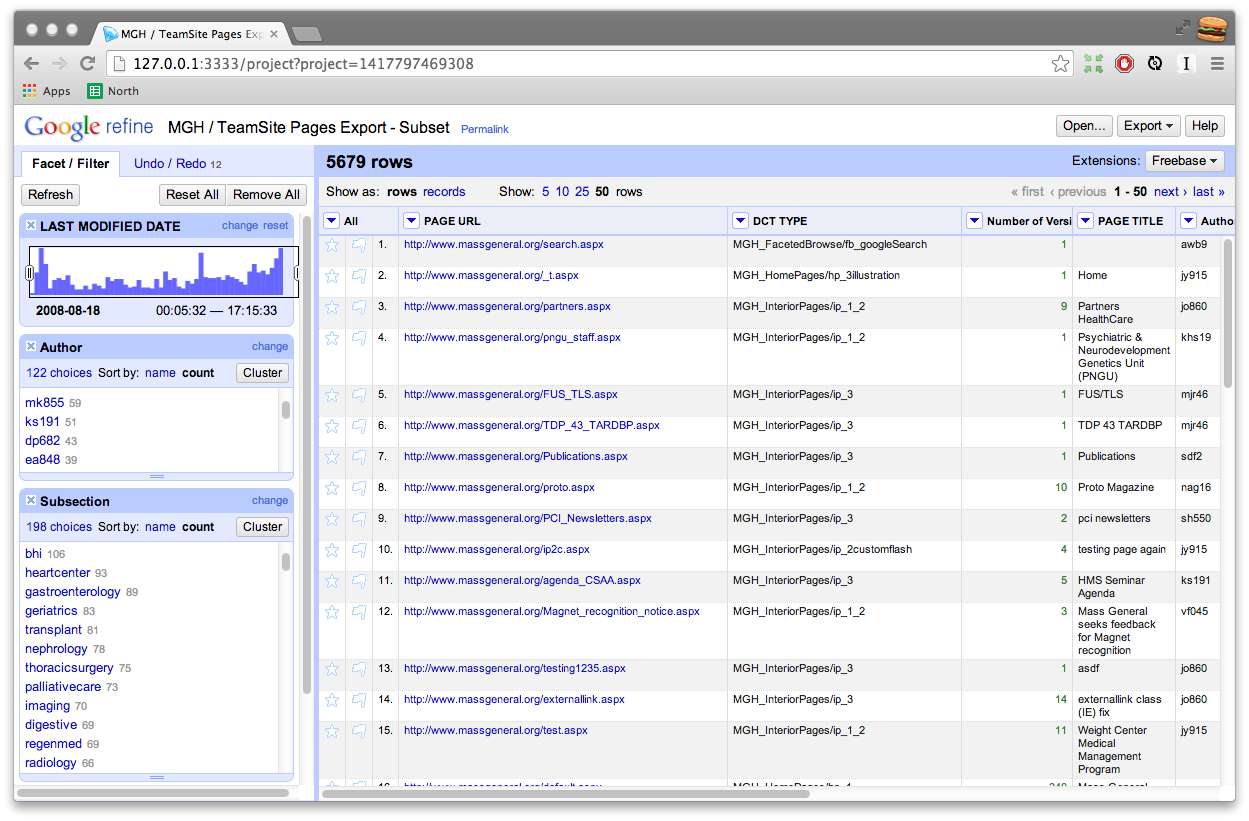
Enter Google Refine (aka Open Refine). Originally developed for people who need to make sense of messy data, OpenRefine is like a spreadsheet on steroids. It really shines when you need to clean up and explore large datasets. While it offers many compelling features, to me, a few things really distinguish this from other tools:
- GREL - an expression language that allows you to slice, dice, and transform content
- Faceting - if you like Pivot Tables (and even if you don’t), you’ll love the iterative faceting that Refine provides.
- Typed Data - the faceting UI chooses an appropriate control based on the column's data type
- Large Datasets - hundreds of thousands of rows aren't really a problem
Using GREL, I was able to extract meaningful information from the URLs like content type and site section. With this and other data, I could use the faceting interface to quickly perform ad hoc queries like: “What pages were last edited between 3 and 10 years ago – and who is responsible?” From there it was easy to produce punch lists of pages for authors to review and cull.
Integrity
On old, unstructured sites, there is often no discernible logic to where pages are placed. Routinely I'm surprised to discover whole sections of content that don’t show up anywhere in the the navigation, the sitemap, or possibly the database export. This poses a problem — how do you know when you’re done? There are unknown unknowns.
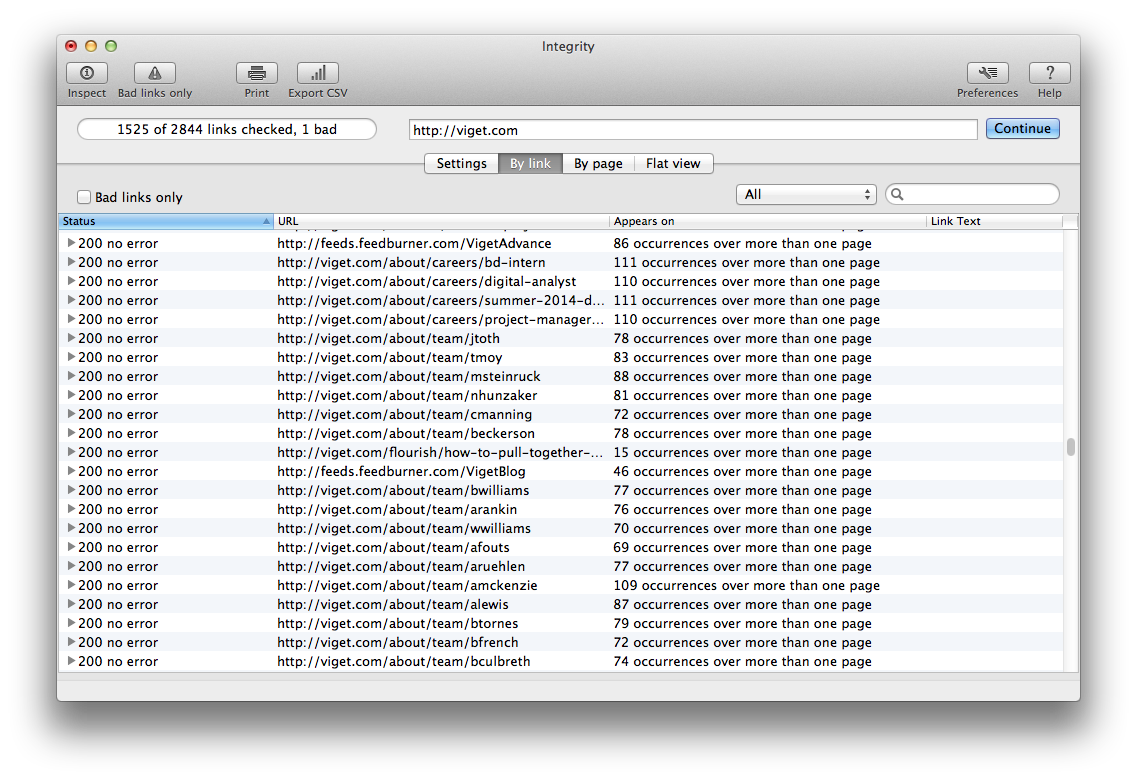
Integrity is a site spider that rips through a site, logging as many pages as it can find within the parameters you set. Originally developed as a QA tool to check links, it complements a manual inventory and clever google searching to reveal as many hidden pages as possible.
Every time I run it – without fail – the results are surprising. I’ve found old campaign sites referenced through press releases, links to undocumented portals, decommissioned products, old versions of the site, and more. Having this data provides a satisfying check against a manual inventory.
What do you use?
These are just a few of the tools I like to employ and I know there are tons more I haven't discovered. If you have any you're particularly fond of, share them in the comments below. And if you're interested in diving deeper, check out related posts posts on visualizing your site as a treemap, creating traffic heatmaps with R, and crafty ways to use Google for content audits.